
Contents
- Rationality, Consciousness and Intentionality
- Descent into Madness
- AI “thought” as illusion and mirage
- ChatGPT 5 hallucinations and fabrications
- AI and Software Engineering
- AI and Pedagogy
The Illusion that AI Machines Think
Large language models (LLMs) have experienced an explosive growth in capability, proliferation, and adoption across consumer and enterprise domains. These models have demonstrated remarkable performance in tasks ranging from natural-language understanding to code generation, using images, audio, and video. But, see The Price of Intelligence, Three risks inherent in LLMs, where hallucinations, indirect prompt injection and jail-brakes are discussed [CACM,August 2025].
 Large Language Models are known to produce overconfident, plausible falsehoods, which diminish their utility. This error mode is known as “hallucination,” though it differs fundamentally from the human perceptual experience by the same name. Despite some progress, hallucinations continue to plague the field. Consider the prompt “What was the title of Adam Kalai’s dissertation?” from three popular language models. None generated the correct title or year (Table 1, in the image above). The correct title is:
Large Language Models are known to produce overconfident, plausible falsehoods, which diminish their utility. This error mode is known as “hallucination,” though it differs fundamentally from the human perceptual experience by the same name. Despite some progress, hallucinations continue to plague the field. Consider the prompt “What was the title of Adam Kalai’s dissertation?” from three popular language models. None generated the correct title or year (Table 1, in the image above). The correct title is:
Adam Kalai. 2001. Probabilistic and on-line methods in machine learning. PhD Thesis. Carnegie, Mellon University.
As soon as one fabrication is fixed in these AI machines, new ones appear elsewhere. ChatGPT-5 gets the above correct, but new hallucinations continue to plague it as we will show below, including confusion about authorship and dates.
Rationality, Consciousness
and Intentionality
Perhaps the most fascinating thing in nature is the human mind. Man is the fusion of a mind and an exquisite body. We are material beings, of course, but we also think, feel, reason and understand. In the modern era, computer science research into artificial intelligence has advanced the materialistic claim that intelligence is the execution of a kind of software on the hardware of the brain. Neuroscience claims that thinking is a byproduct of the unguided processes of neural activity in the brain. However, the idea that science has established these claims lacks evidence and credibility. Even though the human intellect relies on brain activity, the intellect is not solely a brain nor is it a computer.
Contemporary analytic philosophers commonly distinguish between three aspects of the mind which might appear to be inexplicable in materialist terms. Needless to say, not all philosophers think that any of these features really is, at the end of the day, inexplicable in materialist terms. The point is just that it is widely thought that if any mental phenomenon poses a problem for materialism, it will be one or more of these three. The three aspects are rationality, consciousness and intentionality.
Rationality is our capacity to form abstract concepts, to put them together into complete thoughts or propositions, and to reason logically from one proposition to another. For example, we are able not only to perceive this or that particular man, but also to grasp the general idea, or universal concept man, which applies to every man that does, that does exist, has existed, will exist or could exist. We can take this concept and combine it with others to form complete thoughts like the proposition that all men are mortal, and we can infer from propositions like all men are mortal and Socrates is a man, the conclusion that Socrates is mortal. Rationality, in this sense, is among animals unique to human beings.
Consciousness is the awareness of one’s external environment and internal goings on that we and other animals have, and plants and nonliving things do not. In contemporary analytic philosophy, consciousness is taken to be puzzling in so far as it is associated with qualia, the qualitative features of experience, which, unlike ordinary material features, are directly accessible only from the first person point of view of the subject of experience. For example, consider what happens when you look up at the blue sky. There is much neural activity, but there is also a feel to the experience, the quality of the blueness which is directly knowable from within first-person experience.
The third puzzling aspect of the mind discussed by contemporary philosophers is intentionality, which is a technical term for the directedness toward an object that is exhibited by at least some mental states. For example, when you think about the apple tree in your garden, your mind is directed towards or points at that particular object. The intentionality of thoughts is the main example of intentionality discussed by contemporary philosophers, but conscious experiences of the kind even a non-human animal might have seem to exhibit intentionality too. For example, a plant will grow towards the light of the sun. Even though being non-rational, it does not conceptualize the sun the way that we do, and being non sentient, it is not conscious of the Sun the way that a non-human animal can be.
But, it is really rationality that is distinctive of human beings and the key to the immateriality of the mind. However, contemporary philosophers tend to focus instead on consciousness and intentionality as posing the most obvious challenge to materialism. And some of them even seem to think that rationality is relatively easy to account for, as they suppose that the currently popular thesis that the brain is a kind of computer and the mind is the software that runs on the computer, essentially solves the problem of assimilating rationality to matter.
My position is that, at the end of the day, LLMs just shuffle zeros and ones to some very smart algorithms developed by human programmers on vast amounts of training data. Using various stochastic strategies such as gradient descent for next word prediction on neural networks with billions of parameters and trillions of tokens — these algorithms result in imperfect representations of the training data, even if the training data is accurate, real and unbiased. To ensure that these AI machines do not fabricate, hallucinate and descend into madness, they must be closely supervised by human experts. These AI machines provide little (if any) insight into the nature of human understanding of the world, and the nature of consciousness and intentionality required for that understanding. To argue for this position would require book-length treatment. My limited goal here is to discuss some insights many of them of course controversial.
A thought-experiment known as the Chinese Room Argument was first published in a 1980 article by American philosopher John Searle. Searle imagines himself alone in a room following a computer program for responding to Chinese characters slipped under the door. Searle understands nothing of Chinese, and yet, by following the program for manipulating symbols and numerals just as a computer does, he sends appropriate strings of Chinese characters back out under the door, and this leads those outside to mistakenly suppose there is a Chinese speaker in the room. The conclusion Searle draws is that programming a digital computer may make it appear to understand language but does not produce real understanding. Hence the “Turing Test” is inadequate test of intelligence.
Likewise, Roger Penrose quotes Gödel’s incompleteness theorem as evidence that human understanding goes beyond algorithmic computation. For instance, our grasp of mathematical truths about the infinite set of natural numbers ${0,1,2,3,\dots}$—even within the framework of Peano arithmetic—cannot be fully captured by a fixed set of mechanical rules. Gödel’s theorem tells us that, for any set of mechanical theorem-proving rules R, we can construct a mathematical statement G(R) which, if we believe in the validity of R, we must accept as true; yet G(R) cannot be proved using R alone. This is the logical hook Penrose uses in The Emperor’s New Mind (1989) and Shadows of the Mind (1994). He argues that because humans can transcend any fixed formal system, human mathematical understanding is not just the execution of an algorithm. Instead, he sees it as involving non-computable insight—something a Turing machine or formal system cannot fully capture. Gödel’s result reveals a fundamental gap between mechanical symbol manipulation and genuine understanding.
Thus, for any set of algorithmic rules (given to a computer for example), there are statements that the mind of the mathematician understands as indubitably true, but which cannot be derived by any computation from those rules. Human intelligence requires understanding, understanding requires awareness and none of that is computable.
Descent into Madness
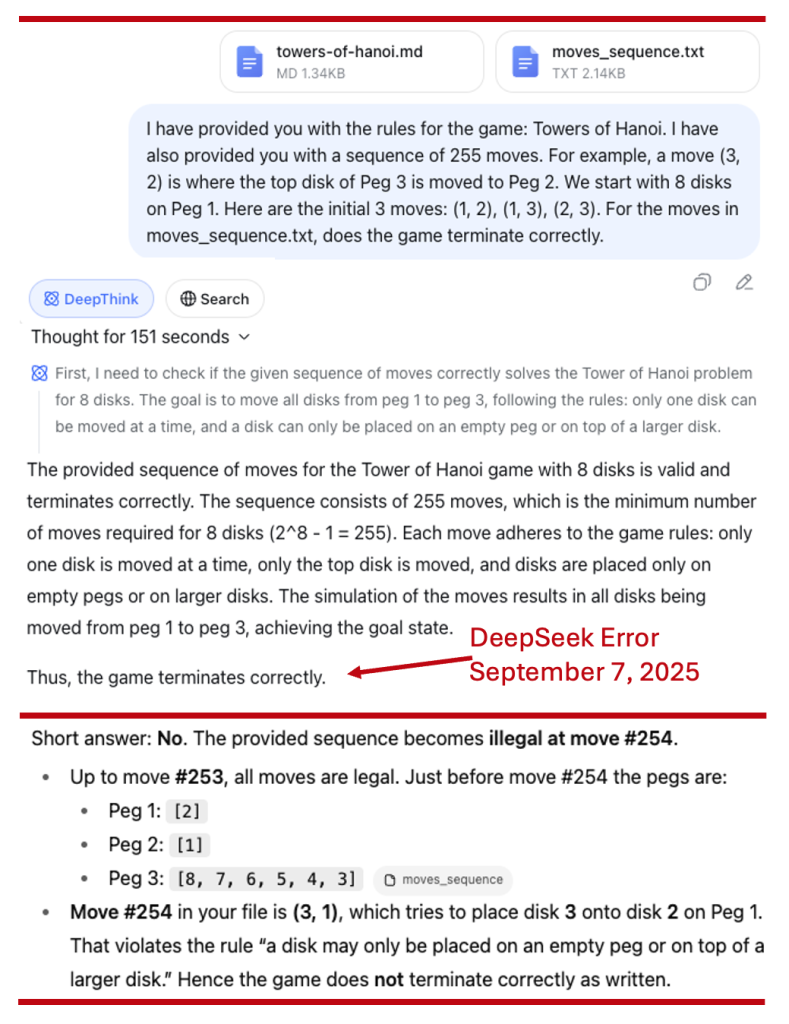
In the figure below a machine learning engineer plots a “descent into madness” of an LLM. It can be best explain with a coding pattern (that I have seen on all recent AI machines). A “descent into madness” in this context is a feedback loop where each attempt to resolve a coding error only re-introduces the original failure, trapping the system (and the user) in a cycle. The LLM suggests program A. That program has some error. You report the bug to the LLM and it suggests a fix, so now you have a revised program B. Now B also crashes with a new error, which you report to the LLM, and request a fix, only to have the same error in program A repeat itself. No amount of prompting can get the LLM to break out of this non-terminating irrational cycle of errors. We will discuss these hallucination loops more in the sequel.

(Above: Tris Oaten, AI Is Not Designed for You, 6 December 2024, youtu.be/6Lxk9NMeWHg)
However, Sam Altman, the CEO of OpenAI, says that his company’s new product — GPT-5 — constitutes “a significant step along the path to AGI” (or artificial general intelligence, the holy grail of current AI research). He insists that it’s “clearly a model that is generally intelligent.” Reid Hoffman, an early donor to OpenAI and former board member, goes even further in declaring that GPT-5 “is Universal Basic Super-intelligence.”
Not all agree with these extravagant proclamations. Forbes says that GPT-5 “clearly is neither AGI [nor] artificial superintelligence.” The MIT Technology Review reports something similar: “The much-hyped release makes several enhancements to the ChatGPT user experience. But it’s still far short of AGI.” And the cognitive scientist Gary Marcus, a critic of LLM hype and hyperbole writes that “GPT-5 is not the huge leap forward people long expected.” The same goes for the other LLMs such as Grok, Gemini, Claude and DeepSeek. One of the main problems are the fabrications and hallucinations that are endemic to these AI machines [“What if AI does not get much better than this?”, New Yorker, 12 August 2025].
If you’ve been working with large language models for a while, you’ve probably noticed something: those shiny new “reasoning” models like OpenAI’s o1, DeepSeek-R1, and Claude’s thinking variants aren’t quite the game-changers they were marketed to be. Sure, they can solve some math problems better, but there’s always been this nagging feeling that something fundamental is missing. And do they truly understand complex tasks — or are they just cleverly mimicking solutions?
This paper from Apple Research, “The Illusion of Thinking,” digs into that question with surgical precision. Using cleverly constructed puzzles and controlled experiments, the authors show that current reasoning-enabled LLMs (a.k.a. Large Reasoning Models or LRMs) exhibit clear limits. In fact, once the complexity of a problem hits a certain threshold, these models stop trying altogether — despite having plenty of computation left to use.
This confirms what many of us have been quietly thinking: these Large Reasoning Models (LRMs) aren’t actually reasoning in any meaningful sense. They’re just very sophisticated pattern matchers that happen to write out their “thoughts” [using (Chain-of-Thought] before giving answers. And more importantly, they hit a hard wall when problems get complex enough. [The Illusion of Thinking, medium.com, Jun 8, 2025. See Anthropic’s pushback on the Apple paper, which to me are more like quibbles than a refutation.]
From the abstract of the Apple research (2025):
By comparing LRMs [Large Reasoning Models] with their standard LLM counterparts under equivalent inference compute, we identify three performance regimes: (1) low complexity tasks where standard models surprisingly outperform LRMs, (2) medium-complexity tasks where additional thinking in LRMs demonstrates advantage, and (3) high-complexity tasks where both models experience complete collapse. We found that LRMs have limitations in exact computation: they fail to use explicit algorithms and reason inconsistently across puzzles. We also investigate the reasoning traces in more depth, studying the patterns of explored solutions and analyzing the models’ computational behavior, shedding light on their strengths, limitations, and ultimately raising crucial questions about their true reasoning capabilities.
Large reasoning model (e.g. using Chain-of-Thought) computation is analyzed on controllable puzzles — Tower of Hanoi, River Crossing, Checker Jumping, Block world — spanning compositional depth, planning complexity, and distributional settings.
Tower of Hanoi is a puzzle featuring three pegs and n disks of different sizes stacked on the first peg in size order (largest at bottom). The goal is to transfer all disks from the first peg to the third peg. Valid moves include moving only one disk at a time, taking only the top disk from a peg, and never placing a larger disk on top of a smaller one. The difficulty in this task can be controlled by the number of initial disks as the minimum number of required moves with n initial disks will be 2^n – 1.
Below are some of the results in which accuracy progressively declines as problem complexity increases until reaching complete collapse (zero accuracy) beyond a model specific complexity threshold.
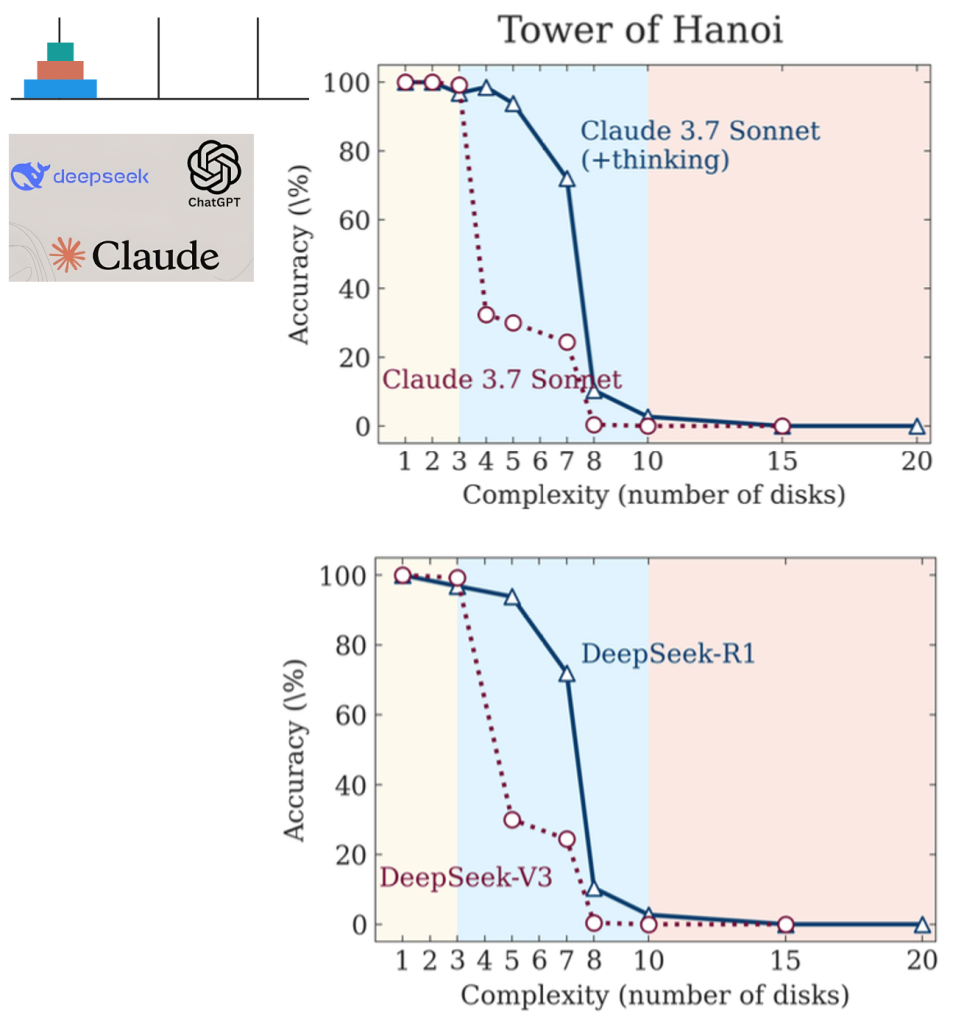
- First regime (3 disks) where problem complexity is low, the non-thinking models obtain performance comparable to, or even better than thinking models with more token-efficient inference.
- Second regime with medium complexity (about 6 disks), the advantage of reasoning models capable of generating long chain-of-thought begin to manifest, and the performance gap between model pairs increases.
- Third regime is where problem complexity is higher (7 or more disks) the performance of both models start collapsing to zero. Results show that while thinking models delay this collapse, they also ultimately encounter the same fundamental limitations as their non-thinking counterparts. Almost everything the model generates is wrong, regardless of position in the thinking trace (Chain-of-Thought). More Tokens ≠ Better Thinking. Surprisingly, models “think” less as problems get harder. Even more surprisingly, even when they are given explicit algorithms they fail to compute correctly. These AI machines don’t generalize, don’t reason, and don’t scale much past training data.
Research indicates that there are large inconsistencies between Chain-of-Thought (how AI machines supposedly “reason”) and actual answers it provides. This inconsistency is shown in mathematical tasks consisting of basic arithmetic calculations such as simple addition and word problems. So Chain-of-Thought does not consistently improve task performance nor does it reveal that there is actual reasoning occurring.

Chain-of-Thought and Answer do not align (arXiv:2402.16048v1, 25 Feb 2024).
“A considerable portion (over 60%) of Addition samples exhibit this unusual behavior, where the reasoning steps are incorrect but yield the correct answers. This pattern persists even with larger LLMs, where the proportion increases to 74% on GPT-4, suggesting that the problem may not be solved by simply enlarging the model.”
AI “thought” as illusion and mirage
The Apple researchers are not the only ones to talk about LLM reasoning as an illusion:

In a recent pre-print paper, researchers from the University of Arizona summarize this existing work as “suggesting that LLMs are not principled reasoners but rather sophisticated simulators of reasoning-like text.” To pull on that thread, the researchers created a carefully controlled LLM environment in an attempt to measure just how well chain-of-thought reasoning works when presented with “out of domain” logical problems that don’t match the specific logical patterns found in their training data. The results suggest that the seemingly large performance leaps made by chain-of-thought models are “largely a brittle mirage” that “become[s] fragile and prone to failure even under moderate distribution shifts,” the researchers write. “Rather than demonstrating a true understanding of text, CoT reasoning under task transformations appears to reflect a replication of patterns learned during training.” [Slashdot, 11 August 2025]
ChatGPT 5 Hallucinations and Fabrications
Due to the stochastic nature of LLMs, it is hard to provide examples that guarantee good or bad results. What works in one run fails in the next. What fails on one of the AI machines (e.g. ChatGPT, Gemini, Claude, Grok, etc.) works on the next. My own experience indicates that LLMs can be helpful in smaller well-defined examples where they are carefully supervised by competent users.
Here are two examples with ChatGPT 5 (2025-09-04).
Example: ChatGPT uses Mistaken Logic
In the figure below, I show the initial query, the first part of the answer, and the last part where ChatGPT provides a mistaken answer.

The correct answer is “Jumbo is not sleepy” is Uncertain.
Consider the following statements:
- Tautology: 2 + 1 = 3
- Contradiction: 2 + 1 = 4
- Contingent: x > 7
The statement 2 + 1 = 3 is True. The statement 2 +1 = 4 is False. However, the statement x > 7 is neither true nor false, it is Uncertain, as it depends on the value of x.
Now consider a conditional statement: If it is raining then there are clouds. In logic this is written:
raining → clouds
This conditional statement does not assert that there are clouds; it merely asserts that under the condition that it is raining there must be clouds.
- Correct answer: The conclusion “Jumbo is not sleepy” is uncertain given the premises. It is neither true nor false.
- So where did ChatGPT-5 go wrong? ChatGPT tried a variety of informal strategies to answer the question. Here is one of them.

In its Chain-of-Thought, ChatGP-5 lapsed into confusion about the nature of conditional propositions.
- Premises 5 and 6 are conditional: They only specify what must be true if Jumbo is a living being (5) or if he is sleepy (6), but do not affirm that either condition actually holds. ChatGPT does not “understand” the nature of a conditional. A conditional statement like P → Q (“If P, then Q”) does not assert that P is actually true—it only restricts what must be true if P happens to be true. ChatGPT treats the conditionals as though their antecedents are automatically true.
- No direct assertion about Jumbo: The premises never assert explicitly that Jumbo is a living being, mammal, elephant, or baby elephant. Thus, there is no contradiction in assuming Jumbo simply lacks these properties. “Jumbo” might just as well be a large milkshake.
- Existential statement (4) is unrelated: The existential claim about “some baby elephants” being sleepy is entirely non-committal about Jumbo specifically.
- No contradiction is forced: The ChatGPT pattern matching computation incorrectly assumes that being sleepy commits Jumbo to a property (such as living being) that triggers contradiction, when in fact the premises allow for scenarios where Jumbo avoids all properties (not being a living being, mammal, elephant, etc.), avoiding any contradiction.
- “Jumbo is sleepy” does not force a contradiction unless further premises are added to guarantee Jumbo’s relevant status. The possibility that Jumbo simply has none of the required properties is a consistent and overlooked scenario.
More importantly, ChatGPT 5 does not really “understand” conditionals. When it gets the answer right is at best a side-effect of its pattern matching algorithm.
Note that ChatGPT did not use a theorem prover to reality check its conclusion (e.g. umsu.de/trees/). Below, the theorem prover provides a logical proof for:
Premises ⊨ Conclusion
i.e. the Premises p ∧ (p→q) entail ( ⊨ ) the conclusion q.

The symbol “∧” stands for “and” which is conjunction. The symbol “¬” stands for not or negation, and it is a proof by contradiction.
If Sx stands x is sleepy then Sj stands for Jumbo is sleepy. Below we check our informal reasoning about Jumbo using the prover. The prover demonstrates that (a) the premises do not entail Sj and (b) the premises also do not entail ¬Sj. Thus Sj is Uncertain.

Clearly, ChatGPT failed to “understand” the logic. It also attempted a proof by contradiction but lost track of the logic along the way. Stochastic next-word pattern matching is a computational heuristic that can only go so far even on this modest example of reasoning. Desk calculators (arithmetic) and theorem provers (logic) using verified algorithms do not lapse into these types of LLM confusions.
ChatGPT 5 Conflates Authors
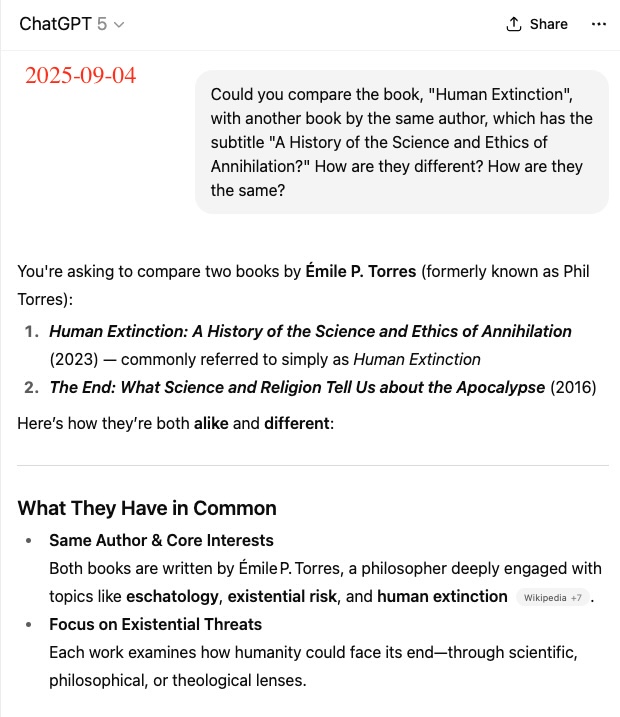
In its response to the above query, ChatGPT 5 has confidently conflated two very different authors with different values and philosophies. There are two very different books:
- Phil Torres, The End: What Science and Religion Tell Us about the Apocalypse, Pitchstone Publishing, 2016.
- Émile Torres, Human Extinction: A History of the Science and Ethics of Annihilation, Routledge, 2023.
The mistake made by ChatGPT 5 is a serious error of authorial conflation—treating two distinct authors as one, and ascribing works produced by different individuals to the same person, resulting in a misleading picture of their philosophical outlooks and literary contributions.
Phil Torres and Émile P. Torres are not interchangeable; despite a similarity in their names and interests, they are associated with different values, academic backgrounds, and philosophical stances, and have produced independent scholarly work with distinct approaches to existential risk and eschatology. For example, the book by Phil Torres analyzes the motivations behind specific religiously inspired threats:
Needless to say, The End will almost definitely inspire controversy among religious groups. It focuses particularly on Muslim extremism, providing analysis of the apocalyptic motivations of the Islamic State and Al-Qaeda that may prove enlightening to Western audiences and may offend Muslim ones [Foreword Reviews 2016, https://www.forewordreviews.com/reviews/endangered-edens/].
In scholarly and academic contexts (as opposed to blogs), misidentifying authors and conflating their works undermines basic standards of intellectual honesty and bibliographical accuracy, misguiding readers and researchers who rely on correct citation and theoretical lineage. The conflation can lead to significant misunderstanding regarding the substance, aims, and ethical perspectives of the books being compared.
In sum, ChatGPT 5’s mistake — stated with admirable confidence — is a bibliographical and philosophical misrepresentation, compromising the accuracy and reliability of scholarly discussion about authorship and ideas in risk literature.
AI and Software Engineering
When AI companies release new versions of their LLMs, they will often use benchmarks to show the improvement over competitors. One such benchmark for software engineering is called SWE-bench.
The SWE-bench (Software Engineering Benchmark) dataset is created to systematically evaluate the capabilities of an LLM in resolving software issues. The dataset contains 2,294 complex issues from GitHub. Given as input the issue information to an LLM, the task for the LLM is to modify the code base to resolve the issue. Each input for an issue consists of a description and a pull request with a reference to the corresponding buggy code repository. Each issue can be either a bug report or a new feature request. The pull request contains the code changes made by developers to address the issue, along with test cases designed to check if the feature is properly implemented or if the bug is successfully fixed.
For example, OpenAI claimed that its model, o3-mini, achieves 49.3% accuracy on the SWE-Bench Verified benchmark a rapid and substantial improvement over earlier large language models. Prior benchmarks on the same dataset reported a slightly earlier model GPT-4o achieving only 18.83% accuracy.
An independent study from researchers at the Lassonde School of Engineering, York University, found major flaws in the SWE-benchmark, significantly lowering GPT4o’s actual performance (from 18.83% to 3.83% accuracy). Many of the AI machine fixes are described as suspicious, including “cheating” and tests so weak that even an incorrect solution can pass the tests. These Al machines are not good at solving software issues on the kind of work that you might give a junior programmer. [arXiv:2410.06992v2, October 2024].
Large Language Models (LLMs) in Software Engineering (SE) can offer assistance for coding. … However, a systematic evaluation of the quality of SWE-bench remains missing. In this paper, we addressed this gap by presenting an empirical analysis of the SWE-bench dataset. We conducted a manual screening of instances where SWE-Agent + GPT-4 successfully resolved issues by comparing the model-generated patches with the actual pull requests. SWE-Agent+GPT-4 was at the top of SWE-bench leaderboard during the time of our study. Our analysis reveals some critical issues with the SWE-bench dataset:
- 32.67% of the successful patches involve “cheating” as the solutions were directly provided in the issue report or the comments. We refer to as ‘solution leakage’ problem.
- 31.08% of the passed patches are suspicious patches due to weak test cases, i.e., the tests were not adequate to verify the correctness of a patch. When we filtered out these problematic issues, the resolution rate of SWE-Agent+ GPT-4 drops from 12.47% to 3.97%. We also observed that the same data quality issues also exist in the two variants of SWE-bench, i.e., SWE-bench Lite and SWE-Bench Verified.
- In addition, over 94% of the issues were created before LLM’s knowledge cutoff dates, posing potential data leakage issues.
This means GPT-4o’s original claim was inflated. The real accuracy must be deflated by a factor of \( \frac{3.83}{18.83} \approx 0.203 \).
If GPT-o3-mini has the same failure patterns as GPT-4o, we would have to apply the same kind of correction factor \(0.203\) to its \(49.3\%\) claim:
\[
49.3\% \times 0.203 = 10.0\%
\]
This suggests that GPT-o3-mini’s real accuracy might be around \(10\%\) instead of \(49.3\%\). An independent assessment is needed.
Beyond tests, my experience with LLMs is that they have no concept of software requirements, architecture and design.
- What is the structure of the system?
- What are the software modules?
- What is the relationship between them ?
- Information hiding: What are the externally visible properties of modules at the interface, i.e. the externally visible properties that other modules using it rely upon?
Software designers are experts at developing software products that are correct, robust, efficient and maintainable. Correctness is the ability of software products to perform according to specification. Robustness is the ability of a software system to react appropriately to abnormal conditions. Software is maintainable if it is well-designed according to the principles of abstraction, modularity, and information hiding. We might expect a software developer to master at minimum the following skills.
1. Specification: Describe software specifications via Design by Contract, including the use of preconditions, postconditions, module invariants, loop variants and invariants.
2. Construction: Implement specifications with designs that are correct, efficient and maintainable.
3. Testing: Develop systematic approaches to organizing, writing, testing and debugging software.
4. Analysis: Develop insight into the process of moving from an ambiguous problem statement to a well-designed solution.
5. Architecture: Design software using appropriate abstractions, modularity, and information hiding.
6. Documentation: Develop the ability to write precise and concise software documentation that also describes the design decisions and why they were made.
Let’s see how well Grok 4 (Expert) does with a query for a simple function (2025-09-06).

Grok provides us with an iterative routine with variable n of type long (64 bit integers). There are elements to admire in the code, but there is a vast literature on the factorial function on which the LLMs have been trained. Let’s execute the code:

Oops? A negative integer? Factorial must be a positive integer! Grok responds as follows:

Ok, BigInteger allows for bigger inputs. But Grok claims that BigInteger will provide arbitrary precision arithmetic. That is also not quite right!
BigInteger stores its magnitude as an array int[]. A Java array length is normally bounded by Integer.MAX_VALUE (about 20 billion digits).
That is a lot, but an input more than that limit will again result in overflow. The AI machine does not ask — or take into account — what is really needed: integer inputs to the function up to 10, up to 20, up to billions? With a few instances of BigInteger one might easily freeze their laptop!
If all you need is $0 \leq n \leq 12$ then the following specification suffices (using a recursive implementation).:

In the above we provide a specification with a precondition (require) and a postcondition (ensure). Note that we can change the implementation (the part between do and ensure) while the specification remains the same. Other functions or modules that use this function may continue to rely on the guarantees provided by the specification. The programmer can change the implementation (e.g., to achieve higher efficiency) provided he proves that the new implementation satisfies the specification.
Even in the small (a single function) there are no signs of competent design. Clearly, current advanced AI machines are computing well below the level of abstraction, specification and design. These machines are certainly not yet ready at this time to be used on safety or mission critical systems, except under very strict and competent human supervision.

The above research paper describes a program-proving environment, which formally determines the correctness of proposed fixes, to conduct a study of program debugging with two randomly assigned groups of programmers, one with access to LLMs and the other without, both validating their answers through proof tools.
In software engineering as in other disciplines, the succession of reactions when one starts using LLM is often a seesaw: alternated “Wow, see what it just did!” and “Wow, see how wrong it is — hallucinating again!” reactions. LLMs have been shown to produce fundamentally wrong solutions with airs of absolute assurance. Hence the idea of complementing the impressive but occasionally wayward creativity of LIMs with the boring but reassuring rigor of formal verification techniques supported by mechanical proof tools. That is what the study reported in this article does. We presented a group of programmers with:
• A set of buggy programs.
• A request to find and correct the bugs.
• Access to a set of state-of-the-art LLMs – or, for the control group, no such help.
• A formal verification environment (a mathematics-based program prover) to validate the fixes.
A test is only the program’s result on one set of inputs, not a specification. With a specification, a proof can be provided which is a mathematical guarantee of correctness for any input. A specification in the form of contract includes a precondition, a postcondition, and a class invariants (in object oriented frameworks), expressing consistency properties of all instances. A program – possibly resulting from an attempt at correcting a buggy first version, passes verification if all creation procedures of a class ensure its class invariant, and every feature, executed with its precondition and class invariant satisfied, terminates with its postcondition satisfied and the invariant satisfied again. The theorem prover must also prove termination for all possible inputs satisfying the precondition.
There are 9 tasks altogether, each consisting of an Eiffel class with a buggy feature (method, routine). The tasks are of varying complexity and difficulty levels; they are drawn from several sources including common examples from formal verification tutorials and bug databases. Task 9 (the most difficult) is a class that defines a routine that attempts to find the first occurrence of key in a sorted array using a binary search strategy but contains logic errors: when the key is less than the middle element, it fails to shrink the search interval properly, potentially causing an infinite loop or incorrect result. The diagrams below use blue for the group that used AI and orange for the group that did not. Here are a few of the results.

Observations: The information on time spent is not very conclusive but suggests that LLM help is somewhat effective for the easier tasks. For the harder tasks, LLMs helps for Task 8, but then no LLM-helped participants finished Task 9, the hardest.

Observations: Here a worrying phenomenon seems to affect hopes of using LLMs for correcting programs, spending far too much time in a useless direction. In observing participant sessions, we noticed a number of “hallucination loops”, where the LLM was giving wrong advice and the participant got hooked with no prospect of success.
A real risk observed in a number of sessions is the hallucination loop. The AI tool makes an incorrect guess about how to correct a bug; the programmer tries it, the result does not verify, the programmer tries to fix it, and gets into a fruitless try-verify-fail loop. The problem is that a fix might look plausible but, in the current state of generative AI, have no conceptual basis. A typical scenario occurs for the most challenging tasks (8 and 9) of the present study, for which the LLM was unable to produce a correctly fix. Verification of its proposed code failed; usually, the participant still failed to understand the cause after several iterations.
Another aberrant behavior, where using the LLM actually harms the programmer, is a variant of the hallucination loop, the noisy solution. The code proposed by the LLM actually contains the solution, but also includes, along with the correct elements, irrelevant ones which prevent or delay the programmer from obtaining a correct fix. Copy-pasting the solution will not work. An example of such behavior occurred in Task 9: the participant provided the buggy code to the LLM, which reported multiple issues (some of them are irrelevant or spurious) and suggested several possible fixes; the participant tried out these suggestions one by one but, before reaching the correct one, became frustrated and gave up.
More generally, the LLM often exhibits the neutrality flaw: it presents various solutions, some potentially useful, others worthless or harmful, without indicating their respective likelihood of being helpful. In addition to pointing to an area of clearly needed improvement for LIMs, this phenomenon suggests that programmers using them should not just treat all their suggestions as equally valid but make a systematic effort to rank them. Watching the videos uncovers yet another antipattern: timidity. Some programmers, seeing that an LLM-generated fix is not working after a copyppaste, tried their luck by submitting to the verifier small variations of the AI solution without following a rigorously logical process. Poorly thought-out use of AI tools may lead to this unproductive behavior.
Observations: The data is not great advertisement for AI support for debugging. Non-AI-assisted programmers solve more tasks correctly and fewer tasks incorrectly!

AI and Pedagogy
Troy Jollimore earned his Ph.D. in Philosophy from Princeton University in 1999, under the direction of Harry Frankfurt and Gilbert Harman. Jollimore is Professor of Philosophy at California State University, Chico. He has been an External Faculty Fellow at the Stanford Humanities Center and a Guggenheim Fellow. He writes as follows:
I Used to Teach Students. Now I Catch ChatGPT Cheats.
I once believed university was a shared intellectual pursuit. That faith has been obliterated. …To judge by the number of papers I read last semester that were clearly Al generated, a lot of students are enthusiastic about this latest innovation. It turns out, too, this enthusiasm is hardly dampened by, say, a clear statement in one’s syllabus prohibiting the use of AI. Or by frequent reminders of this policy, accompanied by heartfelt pleas that students author the work they submit. …
Of course, should such cheating continue to be wide-spread, it seems inevitable that all college degrees will be worth a good deal less and will perhaps cease to offer any advantage at all. But this outcome is surely of little comfort to those willing to work for their degrees, those who want those degrees to continue to be worth something and to mean something. [thewalrus. ca, 5 March 2025]